[Learn about machine learning from the Keras] — 3.Compiler operation process

This section describes the main operation process of Model.Compiler.
Sample program:
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
model = Sequential([
layers.Dense(512, activation="relu")
])
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.build(input_shape=(None, 784))The keras.engine.sequential class inherits the parent class keras.engine.training.Model, and the compiler function is implemented by this parent class. The function does some checks and settings on the keras.engine.sequential.Sequential object (model).
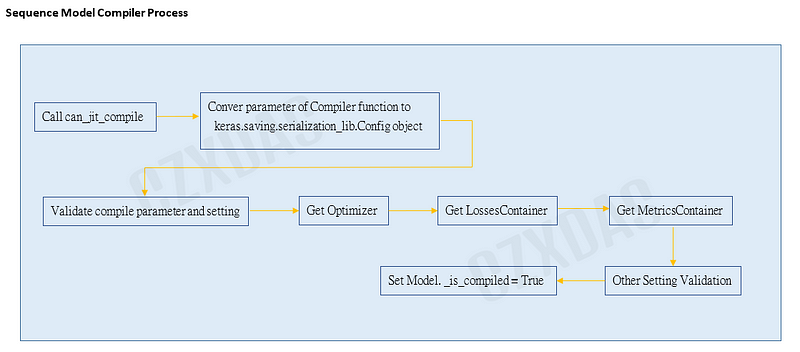
Because it involves the bottom layer of Tensorflow, here is a “rough” look at what compile will do:
(1)
Execute the can_jit_compile function:
The main description of the function is “Returns True if TensorFlow XLA is available for the platform.”
To check the operating system and processor type to determine whether XLA is supported (https://www.tensorflow.org/xla).
If the parameter jit_compile is set to True, but the operating system and processor do not support it (such as Apple ARM), or the GPU is a pluggable device, jit_compile will be stopped.
(2)
keras.engine.sequential.Sequential._compile_config will be assigned the object keras.saving.serialization_lib.Config object, which basically wraps the parameters in this object.
(3)
with self.distribute_strategy.scope()
After this step, it will be related to TensorFlow distributed training. For details, please refer to
https://www.tensorflow.org/guide/distributed_training
If not specified, the default DefaultDistributionStrategy will be used.
tf.distribute.get_strategy() => tensorflow.python.distribute.distribute_lib._DefaultDistributionStrategy
So with self.distribute_strategy.scope()
Instructs Keras which strategy to use to distribute training, by creating models and optimizers within this scope.
(4)
_validate_compile(optimizer, metrics, **kwargs)
Check whether the parameters are legally supported. For example, if the optimization entity of tf.compat.v1.keras.Optimizer, parameter distribute, parameter target_tensors and other parameters except sample_weight_mode exist, exception errors will be caused.
(5)
keras.engine.sequential.Sequential.optimizer = self._get_optimizer(optimizer)
A very important program.
Here we will go to the keras.optimizers.get function to retrieve the optimizer object according to the passed in identifier. The identifier passed in according to the example is the “rmsprop” string.
Generally speaking, if it is not a MAC system, the following modules will be used to find the corresponding optimized module class:
“adadelta”: keras.optimizers.adadelta.Adadelta
“adagrad”: ‘keras.optimizers.adagrad.Adagrad
“adam”: ‘keras.optimizers.adam.Adam
“adamax”: keras.optimizers.adamax.Adamax
“experimentaladadelta”: keras.optimizers.adadelta.Adadelta
“experimentaladagrad”: keras.optimizers.adagrad.Adagrad
“experimentaladam”: keras.optimizers.adam.Adam
“experimentalsgd”: keras.optimizers.sgd.SGD
“nadam”: keras.optimizers.nadam.Nadam
“rmsprop”: keras.optimizers.rmsprop.RMSprop
“sgd”: keras.optimizers.sgd.SGD
“ftrl”: keras.optimizers.Ftrl
“lossscaleoptimizer”: keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
“lossscaleoptimizerv3”: keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
“lossscaleoptimizerv1”:
keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizer
If it is a MAC system, the corresponding optimizer will be found in the following module classes (somewhat different from the above):
“adadelta”: keras.optimizers.legacy.adagrad.adadelta_legacy.Adadelta
“adagrad”: keras.optimizers.legacy.adagrad.adagrad_legacy.Adagrad
“adam”: keras.optimizers.legacy.adam.adam_legacy.Adam,
“adamax”: keras.optimizers.legacy.adamax.Adamax
“experimentaladadelta”: keras.optimizers.adadelta.Adadelta
“experimentaladagrad”: keras.optimizers.adagrad.Adagrad
“experimentaladam”: keras.optimizers.adam.Adam
“experimentalsgd”: keras.optimizers.sgd.SGD
“nadam”: keras.optimizers.legacy.nadam.Nadam
“rmsprop”: keras.optimizers.legacy.rmsprop.RMSprop
“sgd”: keras.optimizers.legacy.gradient_descent.SGD
“ftrl”: keras.optimizers.legacy.ftrl.Ftrl
“lossscaleoptimizer”: keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizer
“lossscaleoptimizerv3”: keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizerV3
“lossscaleoptimizerv1”: keras.mixed_precision.loss_scale_optimizer.LossScaleOptimizer
After finding the corresponding module class, finally use keras.saving.legacy.serialization.deserialize_keras_object to deserialize the parameter settings to form the optimizer module object.
(6)
keras.engine.sequential.Sequential.compiled_loss is set to the compile_utils.LossesContainer object.
If the object passed in as parameter loss is not an entity that inherits keras.engine.compile_utils.LossesContainer (the parent class is keras.engine.compile_utils.Container), then pass
The keras.engine.compile_utils.LossesContainer class generates loss objects.
The LossContainer classes are as follows:
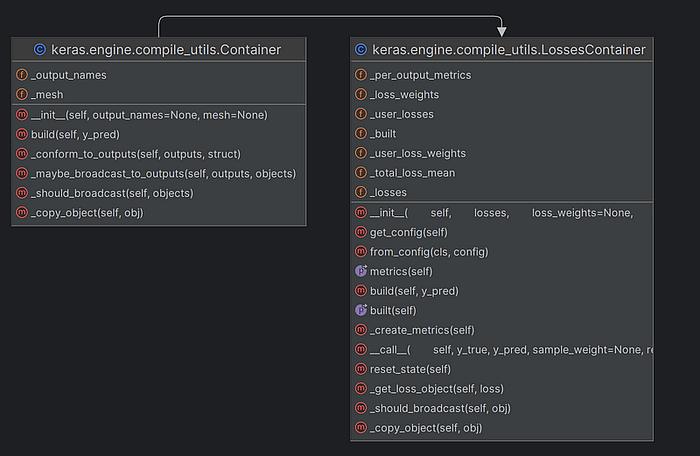
(7)
self.compiled_metrics is set to the compile_utils.MetricsContainer object.
The incoming metrics list is packaged into a class object using keras.engine.compile_utils.MetricsContainer (the parent class is keras.engine.compile_utils.Container), which will check whether there are duplicate names, and if so, an exception error will be generated.
MetricsContainer classes are as follows:
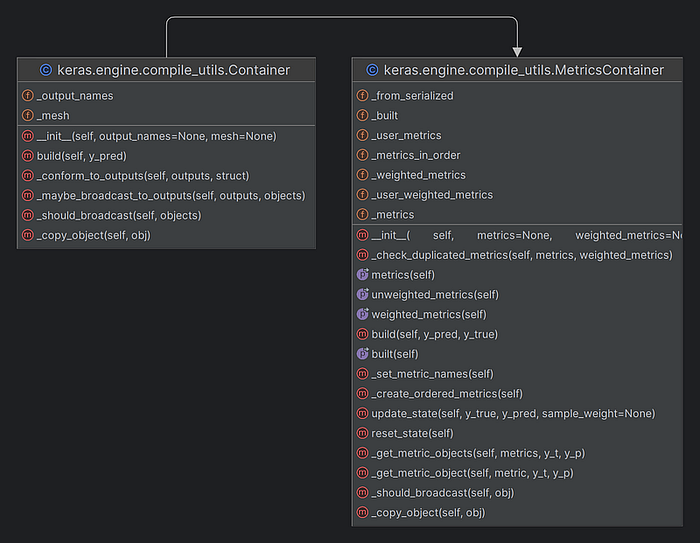
(8)
Check whether the run_eagerly and jit_compile flag variables are enabled at the same time, and generate an exception if so.
(9)
Finally, the _is_compiled variable of its own instance will be set to True, which means there is a successful compiler model.
The above are generally the main things that the compiler will do. If there is no success here, subsequent training cannot be done. So this step is also a step that must be performed.
Just record it here.
