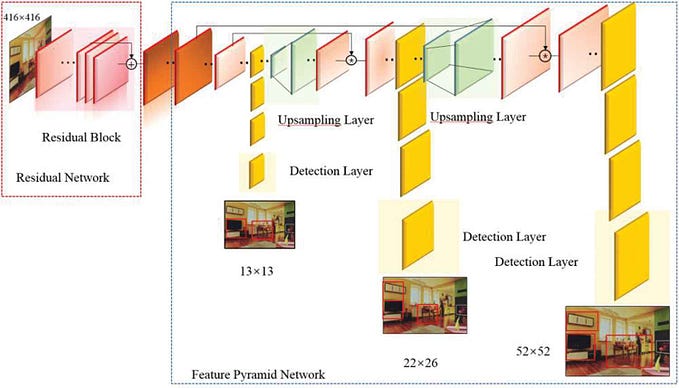
Yolo is one of the favorites in deep learning object detection. It is currently v7, and maybe v8 is about to appear.
Among them, gesture feature point detection is a very cool type of detection, which allows machines to interact with people through these feature recognition.
The open source code provided on GIT can be directly downloaded and executed in the python development environment.
If you need to rewrite a few lines of programs to achieve real-time detection, using a GPU will speed up the performance.
In addition, it is necessary to know where the feature points are located in order to facilitate machine calculation identification.
Instant instance:
Examples of real-time detection by webcam (with face detection without a lot of pauses):
Examples of labeling by video detection:
The main points of several directions achieved are indicated:
1. Download code from GIT source
https://github.com/WongKinYiu/yolov7/tree/pose
2. Originally a read-only file, rewritten so that each frame can be read by openCV
step:
(1) https://github.com/WongKinYiu/yolov7/blob/pose/detect.py : line 23 ~ 24
Original:
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))Change to:
import numpy as np
arr1 = np.array(
[
[254, 254, 254],
[255, 255, 255],
[255, 255, 255]]
)
IsLoadfromCV2 = (type(source) == type(arr1));
if IsLoadfromCV2:
save_img = not opt.nosave # save inference images
webcam = False
else:
save_img = not opt.nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
RtnListKpt = [] # return list(2) https://github.com/WongKinYiu/yolov7/blob/pose/detect.py : line 54 ~ 61
Original:
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)Change to:
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
elif IsLoadfromCV2:
dataset = LodImageFromCV2(imgcv2=source)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)(3) https://github.com/WongKinYiu/yolov7/blob/pose/detect.py : line 116 ~ 119
Original:
if save_img or opt.save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if opt.hide_labels else (names[c] if opt.hide_conf else f'{names[c]} {conf:.2f}')
kpts = det[det_index, 6:]Change to:
if save_img or opt.save_crop or view_img or IsLoadfromCV2: # Add bbox to image
c = int(cls) # integer class
label = None if opt.hide_labels else (names[c] if opt.hide_conf else f'{names[c]} {conf:.2f}')
kpts = det[det_index, 6:]
RtnListKpt.append(kpts) #return list(4) At the end of the detect function, add the return list:
return RtnListKpt(5) https://github.com/WongKinYiu/yolov7/blob/pose/utils/datasets.py :
Add the following class:
class LodImageFromCV2: #load image generate from cv2
def __init__(self, imgcv2, img_size=640, stride=32):
self.imgcv2 = imgcv2
self.count = 0
self.mode = 'image'
def __iter__(self):
self.count = 0
return self
def __next__(self):
if self.count >= 1:
raise StopIteration
# Padded resize
img = letterbox(self.imgcv2, auto=False)[0]
# Convert
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
self.count = 1
return '', img, self.imgcv2, NoneRemember to go back to the top of detect.py to add import this class!
3. Do not read model repeatedly
Original:
# Load model
model = attempt_load(weights, map_location=device) # load FP32 modelChange to:
# Load model
if(cacheModelGuesture==None):
model = attempt_load(weights, map_location=device) # load FP32 model
cacheModelGuesture = model
print('load pose model by weights!')
else:
model = cacheModelGuesture
print('load pose model by cacheModelGuesture!')4. CPU operation is changed to GPU operation
Using the CPU will cause a lot of pauses, and it needs to be changed to a GPU to improve performance:
(1) Download and install the version of Cuda Toolkit that matches the environment (https://developer.nvidia.com/cuda-toolkit)
(2) Download NVIDIA cuDNN (https://developer.nvidia.com/rdp/cudnn-archive), set the directory in the folder to the environment variable
(3) Install pytorch: https://pytorch.org/get-started/previous-versions/ Find instructions that match your cuda version
5. feature point
The content LOG of the feature point LIST generated by the program is as follows (17 points in total):
# 518.39532, 110.67636, 0.99790, #0 nose #1
# 535.50354, 94.94235, 0.99479, #1 right eye #2
# 499.32040, 95.17325, 0.99558, #2 left eye #3
# 556.71338, 95.34943, 0.74167, #3 right ear #4
# 467.37888, 94.00665, 0.74561, #4 left ear #5
# 571.26056, 173.48863, 0.97937, #5 right shoulder #6
# 441.52887, 179.07047, 0.97978, #6 left shoulder #7
# 603.04456, 250.00029, 0.95289, #7 right elbow #8
# 422.85757, 259.88879, 0.95556, #8 left elbow #9
# 652.29517, 296.06424, 0.94478, #9 right hand #10
# 390.21753, 327.82108, 0.94747, #10 left hand #11
# 554.63660, 351.11969, 0.98562, #11 right waist #12
# 473.02588, 357.50790, 0.98591, #12 left waist #13
# 556.95941, 472.08643, 0.96462, #13 right knee #14
# 479.55829, 479.68033, 0.96557, #14 left knee #15
# 584.53955, 560.24908, 0.87556, #15 right foot #16
# 493.19171, 564.42810, 0.87791 #16 left foot #17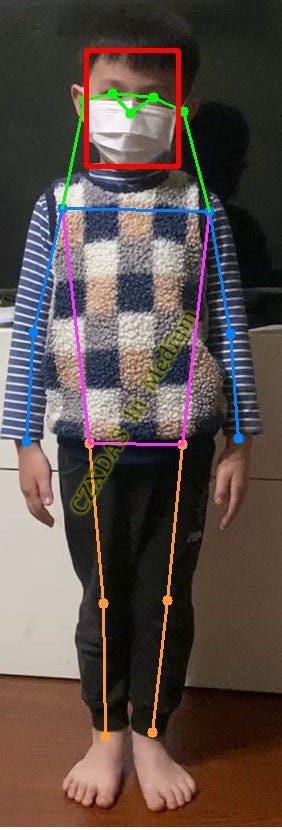
Face detection also uses the same method to return feature points for instant application!
The same way to improve the use of yolo can be used for real-time application of object detection, refer to real time detects and reminds the driver to keep distance.

![[Learn about machine learning from the Keras] — 18.Compute_loss and metrics of the model](https://miro.medium.com/v2/resize:fit:679/1*1D7benYQhY_UoKf2BSwOjg.jpeg)
 17. MediatR — PreProcess and PostProcess](https://miro.medium.com/v2/resize:fit:679/1*FXbQT1uQQwhikTShMVWiNg.jpeg)